
リバースプロキシ構築のため、Apacheについて勉強中。
以下の書籍を読んでいる。
[24時間365日] サーバ/インフラを支える技術 ‾スケーラビリティ、ハイパフォーマンス、省力運用 (WEB+DB PRESS plusシリーズ)
その中で、次のような文章があった。
preforkのApacheの場合、ある一つのhttpd親プロセスがまず起動して、そのプロセスが複数のhttpd子プロセスを生成します(p.199)
fork(フォーク)って何だ?
と、疑問に思ったのでざっくり調べた。
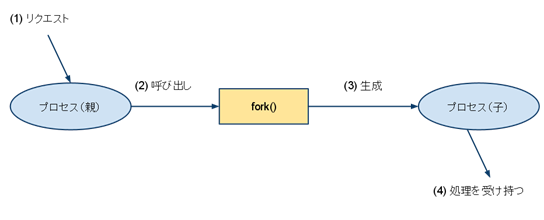
forkとは(図1)
- UNIX系システムコール
- 親プロセスのコピーを生成する
- 親プロセス: fork()を呼び出すプロセス
- 子プロセス: fork()で新たに生成されるプロセス
- 親と子は独立したメモリ空間で動作 → 互いに干渉することはない
- fork時に親kら子へメモリ内容が丸ごとコピー
- コピー処理はコストが高い
- コピーオンライト(メモリコピーの遅延処理)で効率化

図1
forkについてはざっくりとだが分かった。
では、preforkというのは何だ?
pre(事前)が付くので、事前にforkすることなんだろうが、
なぜpreでforkするのか…。
クライアントからリクエストを受けたあとでforkするとfork完了までに待ち時間が出来て通信のパフォーマンスが遅くなる。そのため、あらかじめいくつかの子プロセスをforkしておき、forkの待ち時間をなくす方式をとっている。
コピーオンライト(書込み時にコピー)という用語が出てきたが、何のことだろうか?
一応調べておこう…。
親プロセスと子プロセスは、独立したメモリ空間で動作するが、
fork時に親子で別々のメモリ領域を用意していたのではメモリ使用量が大きくなってしまう。
そこで、forkした段階では親子で物理メモリ領域を共有させる(図2)。
親子で別々の仮想メモリ空間を用意し、物理メモリ領域とマッピングさせる。
親か子の仮想メモリ空間への書込みが発生した時に
はじめて親子で別々の物理メモリ領域(書込み対象分だけ)を用意する(それ以上はメモリを共有できないため)(図3)。
書込みが行われないメモリ領域はいつまでも共有し続けられる。
これによりメモリ上のページの重複を避けてメモリを効率的に利用出来る。

図2

図3

